# hadoop安装
# 本内容你将获得
- hadoop安装环境准备
- Hadoop安装包上传
- CenOS7上安装Hadoop
- 验证Hadoop安装
# 软件安装
# 说明
- hadoop依赖 Java环境
# 环境准备
# 设置免密登录
#安装时进行文件分发
cd /root
ssh-keygen -t rsa
ssh-copy-id -i root@localhost
# 设置hosts
cd /etc
vi hosts
192.168.17.149 hadoopmaster
保存后,ping hadoopmaster 进行网络测试
# 设置hostname
cd /etc
vi hostname
hadoopmaster
保存后reboot服务器使设置的主机名生效
# 安装包上传
# 上传hadoop-3.3.4.tar.gz到服务器/root/tools目录
解压安装包
tar -xzvf hadoop-3.3.4.tar.gz
# 上传jdk-8u333-linux-x64.tar.gz到服务器/root/tools目录
解压JDK包
tar -xzvf jdk-8u333-linux-x64.tar.gz
配置JAVA_HOME环境变量
vi /etc/profile
export JAVA_HOME=/root/tools/jdk1.8.0_333
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
保存后,source /etc/profile 使配置生效
# 安装开始
# 配置hadoop环境变量
vi /etc/profile
# HADOOP env variables
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_HOME=/root/tools/hadoop-3.3.4
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存后,source /etc/profile 使配置生效
# 修改core-site.xml,在<configuration>中增加如下<property>
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.17.149:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
# 修改 hdfs-site.xml,在<configuration>中增加如下<property>
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop_store/hdfs/namenode2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop_store/hdfs/datanode2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
保存后,创建对应的目录
mkdir -p /root/hadoop_store/hdfs/namenode2
mkdir -p /root/hadoop_store/hdfs/datanode2
# 修改mapred-site.xml,在<configuration>中增加如下<property>
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://192.168.17.149:8001</value>
<final>true</final>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/root/tools/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/root/tools/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/root/tools/hadoop-3.3.4</value>
</property>
<!-- 开启jobhistory服务-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.17.149:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.17.149:19888</value>
</property>
# 修改yarn-site.xml,在<configuration>中增加如下<property>
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi yarn-site.xml
<property>
<!-- 为mr程序提供shuffle服务 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.17.149:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.17.149:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.17.149:8050</value>
</property>
<!--日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志信息保存在文件系统上的最长时间 秒为单位-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
<!-- Site specific YARN configuration properties -->
<!-- resource,manager主节点所在机器 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.17.149</value>
</property>
<!-- 一台NodeManager的总可用内存资源 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>12288</value>
</property>
<!-- 一台NodeManager的总可用(逻辑)cpu核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 是否检查容器的虚拟内存使用超标情况 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 容器的虚拟内存使用上限:与物理内存的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- container内存按照默认大小配置,即为最小1G,最大8G -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<!-- 开启jobhistory服务-->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.17.149:19888/jobhistory/logs/</value>
</property>
# 修改hadoop-env.sh
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi hadoop-env.sh
# JAVA_HOME=/usr/java/testing hdfs dfs -ls #设置JAVA_HOME
export JAVA_HOME=/root/tools/jdk1.8.0_333
# export HADOOP_HEAPSIZE_MAX= #设置HADOOP_HEAPSIZE
#<!-- 设置hadoop heap 大小-->
export HADOOP_HEAPSIZE=6000
# 修改yarn-env.sh
cd /root/tools/hadoop-3.3.4/etc/hadoop
vi yarn-env.sh
YARN_HEAPSIZE=6000 #在文件最后增加YARN_HEAPSIZE配置
# 在nameNode服务器上进行格式化
[root@hadoopmaster hadoop]# hdfs namenode -format #日志中出现如下提示,说明格式化成功
2022-09-14 16:00:06,267 INFO common.Storage: Storage directory /root/hadoop_store/hdfs/namenode2 has been successfully formatted
# 启停
cd /root/tools/hadoop-3.3.4/sbin
./start-all.sh --启动hadoop服务
./stop-all.sh --停止hadoop服务
./mr-jobhistory-daemon.sh start historyserver --启动yarn日志功能
./mr-jobhistory-daemon.sh stop historyserver --停止yarn日志功能
# 验证安装
访问前端界面,验证安装是否成功
# 开放防火墙端口
如服务器开启防火墙,开放hadoop如下端口
--hadoop前端端口
firewall-cmd --zone=public --add-port 50070/tcp --permanent
firewall-cmd --zone=public --add-port 8088/tcp --permanent
firewall-cmd --zone=public --add-port 19888/tcp --permanent
--刷新防火墙
firewall-cmd --reload
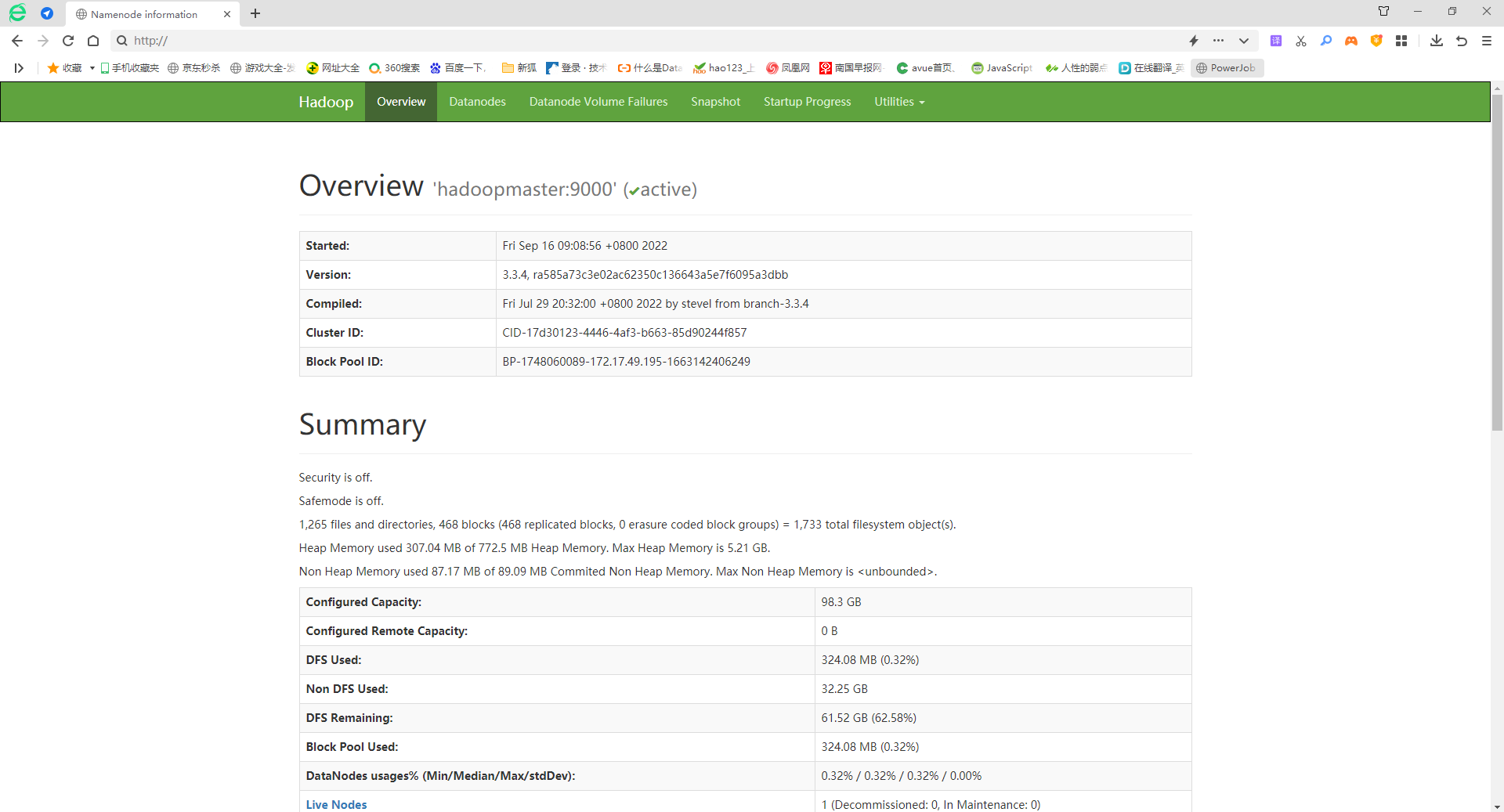
# hadoop前端
网址: http://ip:50070
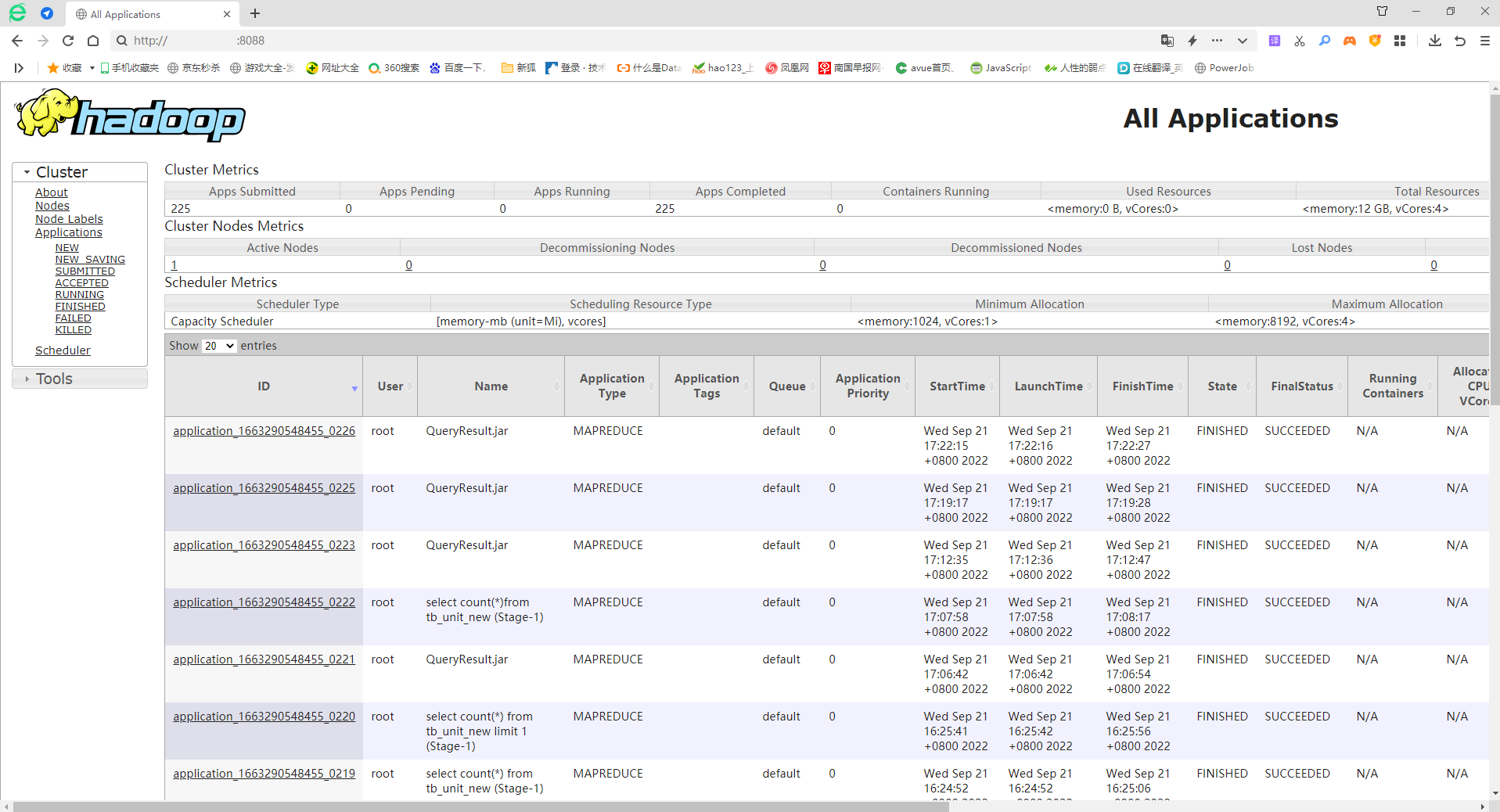
# yarn前端
网址: http://ip:8088
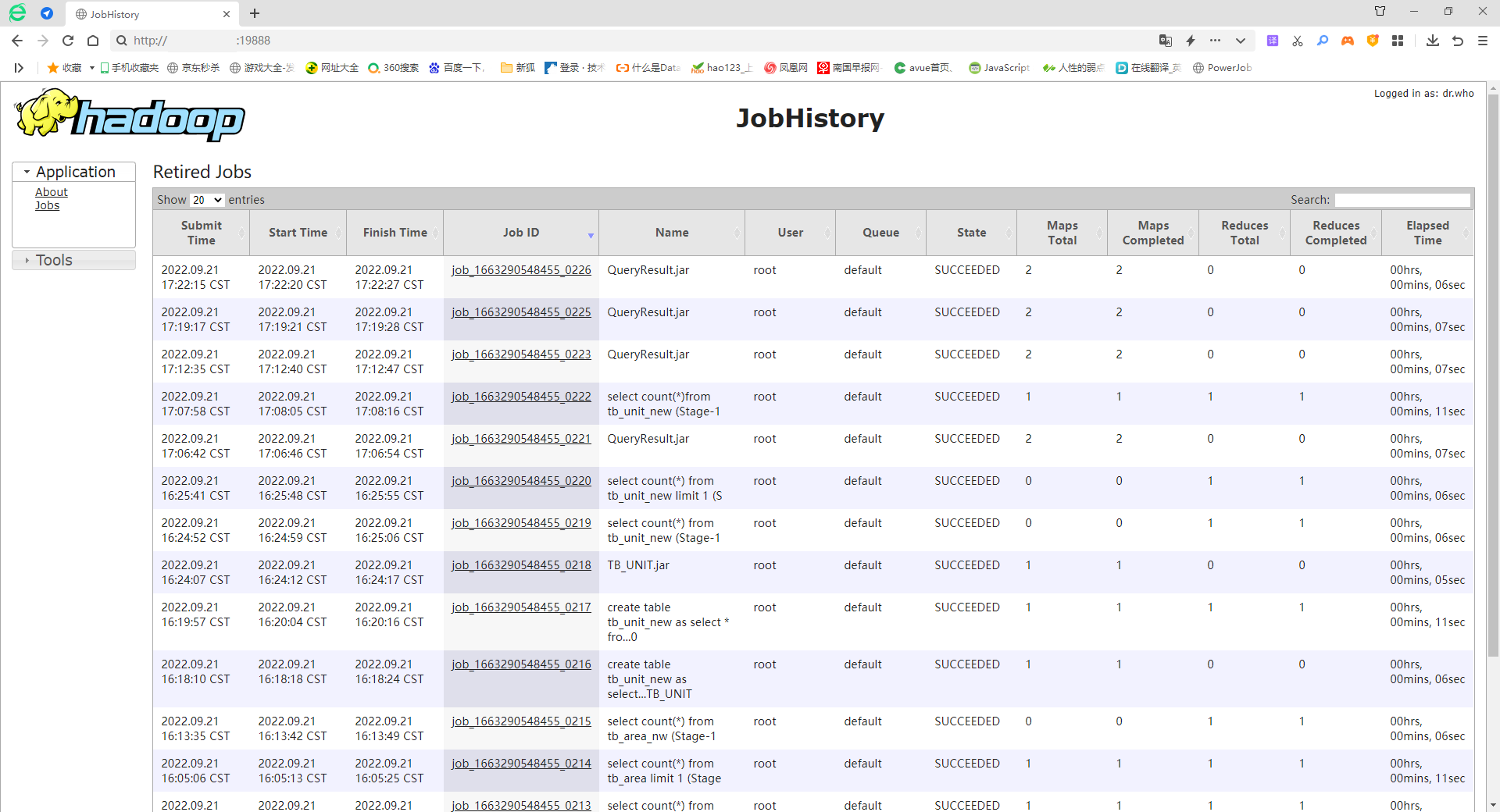
# yarn历史前端
网址: http://ip:19888
# 其他
- 无