# 离线计算
# 概述
核心是数据分析,把大数据离线计算的整套流程和框架搭建起来,后续就是不断在框架中加入新的业务、 新的需求
所谓大数据离线计算,就是利用大数据的技术栈(主要是 Hadoop),在计算开始前准备好所有输入数据,该输入 数据不会产生变化,且在解决一个问题后就要立即得到计算结果的计算模式。
离线(offline)计算也可以理解为批处理(batch)计算,与其相对应的是在线(online)计算或实时(realtime)计算
# 应用场景
- 大数据离线计算主要用于数据分析、数据挖掘等领域。我们说这部分的技术栈主要是 Hadoop,但在 以 Hadoop 为代表的大数据技术出现之前,数据分析、数据挖掘已经经历了长足的发展。尤其以 BI 系 统为主的数据分析领域,已经有了比较成熟稳定的技术方案和生态系统。
- BI(全称为 Business Intelligence,即商业智能)系统能够辅助业务经营决策。其需要综合利用 数据仓库(基于关系型数据库)、联机分析处理(OLAP)工具(如各种 SQL)和数据挖掘等技术。
- 如 Oracle、IBM、Microsoft 等数据库厂商都有自己的 BI 产品,MicroStrategy、SAP 等独立 BI 厂商也 有自己的软件产品。
# 离线计算架构设计
# 架构规划
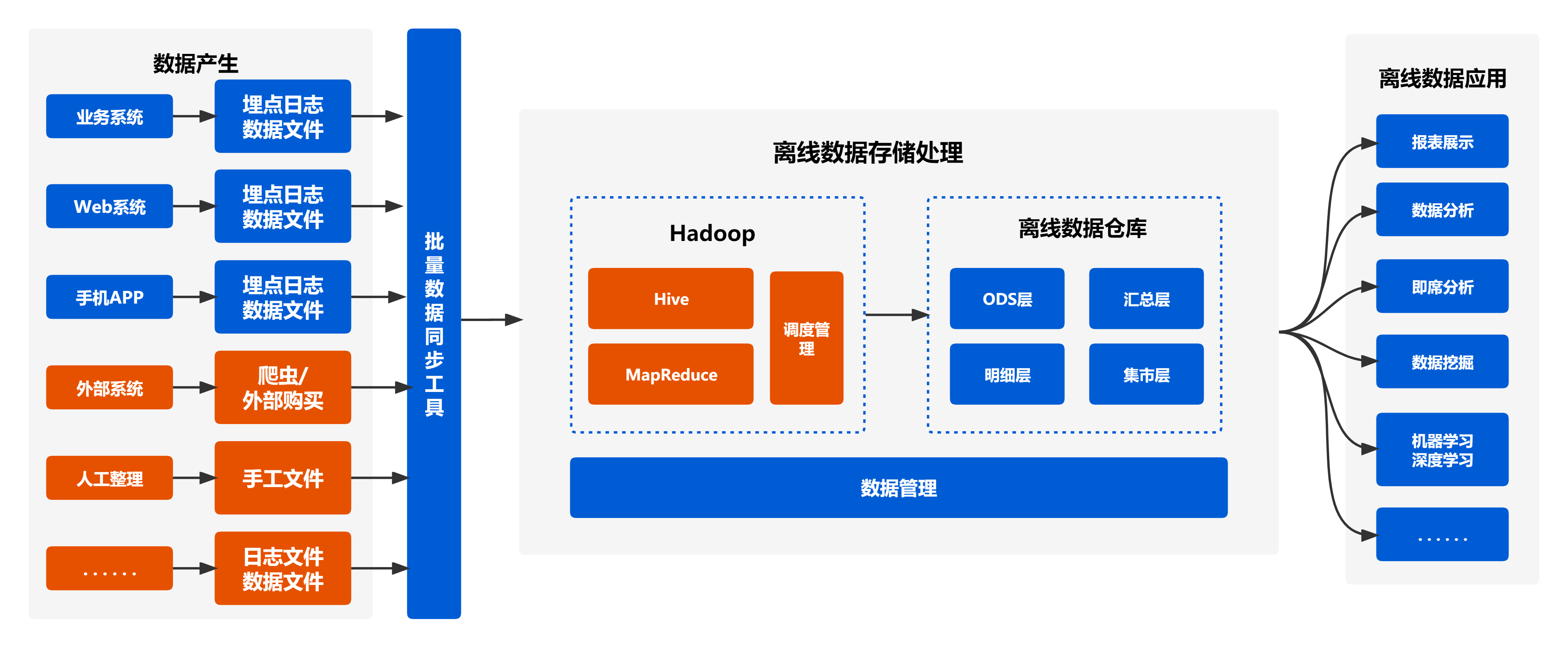
架构说明:
- 数据采集或产生是通过各类日志、埋点、爬虫或手工整理的方式来对需要分析的数据进行收集
- 离线数据存储处理包括了数据清洗、数据存储和数据分析。需要对其不合规的数据(空值或异常数据)进行剔除或处理,将清洗好的数据存储到HDFS系统中(可以通过Hive进行存储,其底层都为HDFS),以便进行分布式计算分析;通过MapReduce、spark进行大数据的分布式计算分析,得出分析结果
- 离线数据应用可将分析结果可视化展示
# 技术规划
版本号以 cdh 指定版本号为主,待调整
| 序号 | 功能 | 技术 | 备注 |
|---|---|---|---|
| 1 | 流计算引擎 | Storm/Spark/Flink/KafkaConsumer | |
| 2 | 消息队列 | Kafka/RocketMQ/阿里云 DataHub/阿里云日志服务 LogHub | |
| 3 | 日志采集工具 | Logstash/Flume/阿里云日志服务 LogTail | |
| 4 | 缓存 | Redis/Memcache | |
| 5 | 数据存储 | RDBMS/NOSQL 数据库/搜索引擎/分布式文件系统 | |
| 6 | 数据查询引擎 | Kylin/Impala/Presto |
# 离线计算特点
- 数据量巨大,保存时间长
- 在大量数据上进行复杂的批量运算
- 数据在计算之前已经完全到位,不会发生变化
- 能够方便地查询计算结果
# 离线开发
以下为离线开发过程主要使用技术
# Hadoop
Hadoop 是一个蓬勃发展的生态,从底层调度和资源管理的 YARN/ZooKeeper 到 SQL on Hadoop 的 Hive,从 分布式的 NoSQL 数据库 HBase 到流计算 Storm 框架,从海量日志采集处理框架 Flume 到海量消息分布式订 阅-消费系统 Kafka,所有这些技术共同组成了一个完善的、彼此良性互动和补充的 Hadoop 大数据生态系统
# 优势:
- 处理超大文件
- 运行于廉价的商用机器集群上
- 高容错性和高可靠性
- 流式的访问数据(一次写入、多次读取)
# 劣势:
- 不适合低延迟数据访问:HDFS 是为了处理大型数据集而设计的,主要是为达到高的数据吞吐量而设计的, 延迟时间通常实在分钟乃至小时级别
- 无法高效存储大量小文件
- 不支持多用户写入和随机文件修改
# Hive
Hive 是建立在 Hadoop 体系架构上的一层 SQL 抽象,使得数据相关人员使用他们最为熟悉的 SQL 语言就可以 进行海量数据的处理、分析和统计工作,而不是必须掌握 Java 等编程语言和具备开发 MapReduce 程序的能力。
# 维度建模
这块主要是先深入理解业务,然后根据各种方法论建模. 在大数据时代,数据量的庞大、数据来源和类型的多元化、数据价值密度低、数据增长快速等特性使 得传统的数据仓库无法承载,因此需要一个新的架构作为大数据的支撑.
# 其它
- 略