# 实时计算
# 概述
离线处理的模式可以满足“看”数据的需求,但是在大数据时代,数据已经不仅局限在"看"。 在很多场景下,需要在数据产生的那个时刻立刻捕获数据,并进行针对性的业务动作(如 广告推送、实时商品推荐、实时新闻推荐等)
# 解决问题
- 源数据非常大时,往往数据的移动就要花费较长时间
- 传统的数据处理工具往往是单机模型,面对海量数据时,数据处理的时间是大问题
# 实时计算架构设计
实时数据采集(如 Flume),消息中间件(如 Kafka)、流计算框架(如 Strom、Spark、Flink 和 Beam 等), 以及实时数据存储(如列族存储的 HBase)
数据来源通常可以分为两类:数据库和日志文件。对于前者,业界的最佳实践并不是直接访问数据 库抽取数据,而是会直接采集数据库变更日志,比如直接使用 binlog
# 架构规划
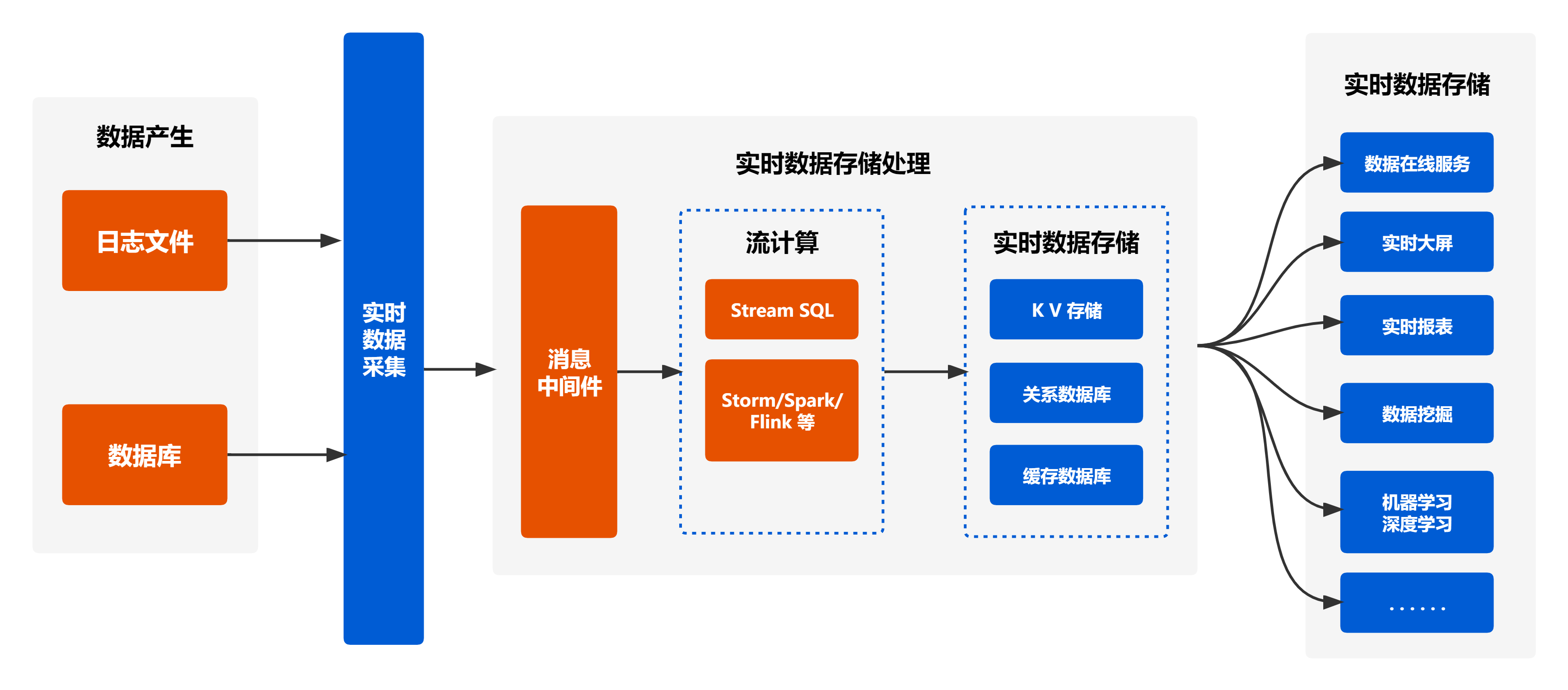
架构说明:
- 数据采集或产生是通过各类日志、数据库的方式来对需要分析的数据进行收集
- 实时数据存储处理包括了数据清洗、流计算和数据存储和数据分析。需要对其不合规的数据(空值或异常数据)进行剔除或处理,将清洗好的数据存储到Kafka系统中(可以通过数据库进行存储,其底层都为Kafka),以便进行流计算分析;通过Stream SQL/Storm/Spark/Flink进行大数据的流计算分析,得出分析结果
- 实时数据存储可将分析结果可视化展示
# 实时计算特点
- 实时,随时可以看数据
- 无边界:数据源源不断
- 触发:何时对数据开始计算
- 延迟:要求低
- 历史数据:Hadoop 离线任务如果发现历史某天的数据有问题,通常很容易修复问题 而且重运行任务,但是对于流计算任务来说基本不可能或者代价非常大,因为首先 实时流消息通常不会保存很久(一般几天),而且保存历史的完全现场基本不可能。
# 应用场景
# 实时 ETL
集成流计算现有的诸多数据通道和 SQL 灵活的加工能力,对流式数据进行实时清洗、 归并、结构化处理。同时,为离线数仓进行有效的补充和优化,为数据实时传输的提供可计算通道。
# 实时报表
实时化采集、加工流式数据存储。实时监控和展现业务、客户各类指标,让数据化运营实时化。
# 监控预警
对系统和用户行为进行实时检测和分析。实时监测和发现危险行为。
# 在线系统
实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略。在各类内容投放、无线智能 推送领域有大量的应用。
# 实时开发
待补充
# 其它
- 略