# 数据采集开发方案
# 概述
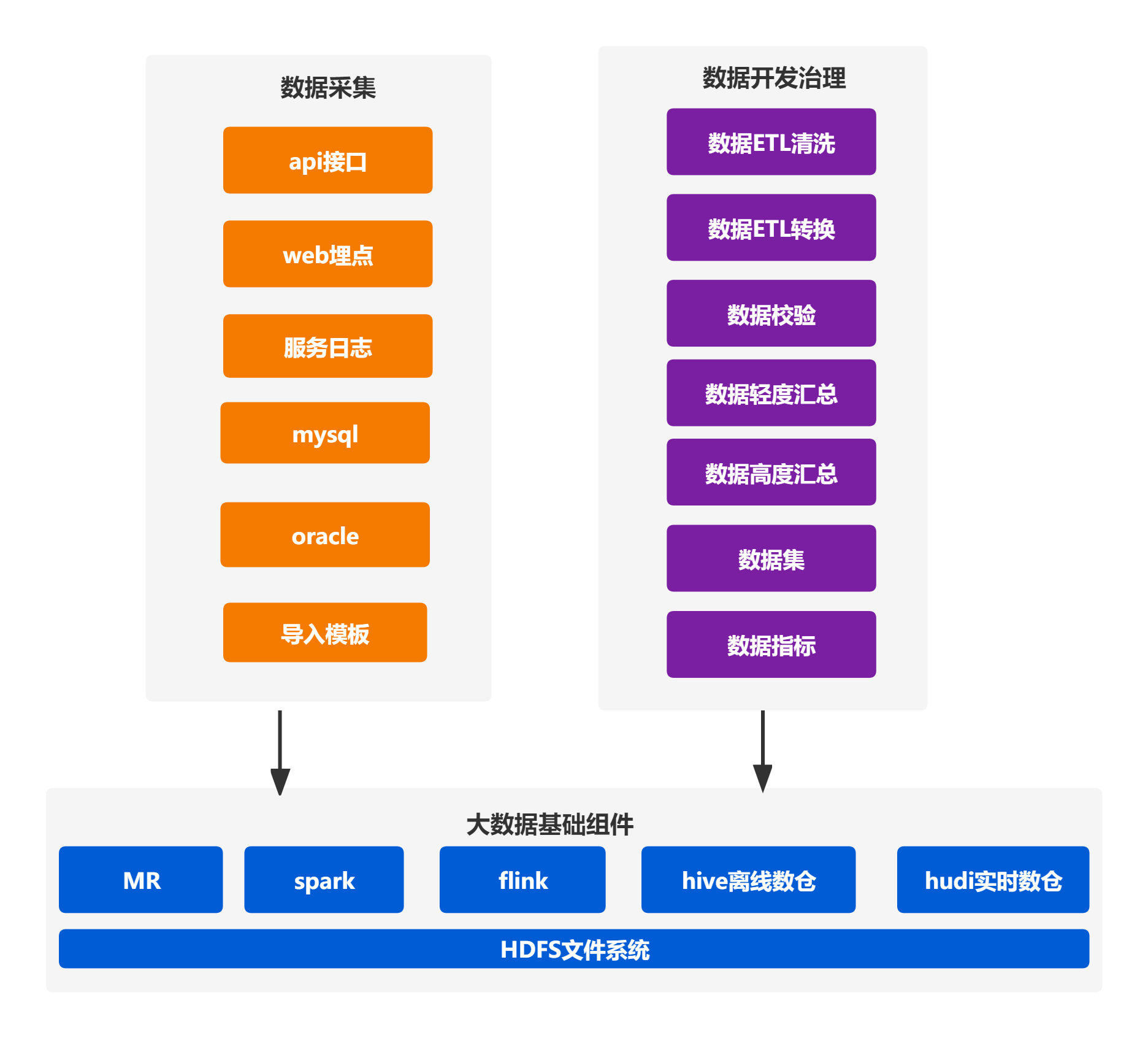
数据集成服务从数据库、结构化半结构化数据、服务器日志、业务系统日志......中采集信息,将经过清洗、转换加工、校验后的数据推送到大数据仓库。数据开发工程师使用数据开发服务对数据进行计算汇总,挖掘出数据。数据开放服务将提炼出的数据呈现到各个业务系统及企业管理者面前。企业管理者从挖掘的结果中获取知识、信息和经验,有助于进行经营分析和总结,提高决策能力,增强企业竞争力
# 方案架构
# 用户场景
# 数据源众多,难以整合
企业数据的展示形式多样、存储格式不一致,难以进行整合处理,进而统计出有用的数据
# 数据量巨大,普通计算机无法处理
随着信息技术的普及,企业在日常经营中积累了海量的数据,PC/笔记本的硬件配置无法提供足够的计算资源处理数据
# 采集方案优势
# 多源数据整合
针对众多的数据源,运用高效地工具进行采集、加工、校验后存入数据仓库,保障数据的完整性、一致性,有利于后期数据开发
# 采集时效
根据业务需求,对一般数据进行时延较长的离线采集;对重要数据作流式处理后,进行实时采集
# 数据库
实时采集:通过配置binlog日志,实时捕获消息写入数仓表
离线采集:首先开发按时间变量提取数据并写入数仓表的任务,然后将任务上传到数据集成服务进行定时调度
# WEB服务日志
实时采集:将服务器日志配置成json格式并写入消息队列,实时捕获消息队列数据写入数仓表
# 格式化数据文件
实时采集:系统提供导入模板,导入时将数据写入消息队列,实时捕获消息队列数据写入数仓表
# 在线任务调度
提供统一的在线调度任务平台,有利于对任务进行管理及监控,降低管理难度,有效地提供工作效率
# web埋点
在业务系统的关键位置进行埋点,实时采集业务数据
# 开发治理方案优势
# 可视化拖拉拽功能
提供在web界面拖拉拽组件设计工作流的功能。将功能组件化后提供丰富的组件,如shell、python、sql、mr、spark、flink等组件
# 多个执行端
一个web管理界面中心,分发任务到多个任务执行端,有利于提供处理效率
# 有向无环工作流
在一个工作流中将数据处理过程分解为若干个有依赖关系的子任务,每个子任使用一个组件进行处理,最终将所有子任务形成一个DAG。通过组合使用多种组件进行数据开发,有利于切换数据处理场景和数据处理工具
# 多种开放框架
将数据存储在hadoop的hdfs文件系统中,可利用hadoop生态圈MapReduce、hive on spark、spark on hive 、flink等执行引擎、计算框架进行数据开发,后期也可使用生态圈内最新的计算框架
# 数据开发时效
根据业务需求,对一般数据进行时延较长的批处理,生成小时报、日报、周报、月报、季报等;对重要数据,进行流式采集实时汇总计算,快速有效地提炼出数据
# 数据治理
在工作流中的子任务中,可以进行数据质量检测,进行数据补齐、过滤及转换,保证计算结果完整、准确
# 数据安全保障
在数据仓库中按用户、数据库、数据表、数据目录等进行授权,防止非法访问,造成数据泄密
# 其他
- 无